|
Hi there! I am a Research Scientist and a member of the founding team at Skild AI. My goal is to build robots that can operate robustly in the wild. Previously, I did my PhD at the Robotics Institute of Carnegie Mellon University, advised by Deepak Pathak and Abhinav Gupta. I have also spent time at Meta AI (FAIR) and at NVIDIA Robotics. Prior to CMU, I did my undergrad at UC Berkeley in Applied Math and Computer Science, where I was affiliated with Berkeley Artificial Intelligence Research (BAIR) and worked with Sergey Levine on problems in deep reinforcement learning and robotics. Feel free to contact me via email! You can reach me at shikharbahl24 -at- gmail dot com email / CV / Google Scholar / Twitter / GitHub |

|
|
|
|
I am broadly interested in creating robust autonomous agents that operate with minimal or no human supervision, in the wild. My research focuses on learning for perception and robot control. Here is some of my work (representative papers are highlighted): |
|
|
|
webpage |
pdf |
abstract |
bibtex |
Large, high-capacity models trained on diverse datasets have shown remarkable successes on efficiently tackling downstream applications. In domains from NLP to Computer Vision, this has led to a consolidation of pretrained models, with general pretrained backbones serving as a starting point for many applications. Can such a consolidation happen in robotics? Conventionally, robotic learning methods train a separate model for every application, every robot, and even every environment. Can we instead train “generalist” X-robot policy that can be adapted efficiently to new robots, tasks, and environments? In this paper, we provide datasets in standardized data formats and models to make it possible to explore this possibility in the context of robotic manipulation, alongside experimental results that provide an example of effective X-robot policies. We assemble a dataset from 22 different robots collected through a collaboration between 21 institutions, demonstrating 527 skills (160266 tasks). We show that a high-capacity model trained on this data, which we call RT-X, exhibits positive transfer and improves the capabilities of multiple robots by leveraging experience from other platforms. |
|
|
webpage |
abstract |
bibtex |
CoRL
Dexterity is often seen as a cornerstone of complex manipulation. Humans are able to perform a host of skills with their hands, from making food to operating tools. In this paper, we investigate these challenges, especially in the case of soft, deformable objects as well as complex, relatively long-horizon tasks. Although, learning such behaviors from scratch can be data inefficient. To circumvent this, we propose a novel approach, DEFT (DExterous Fine-Tuning for Hand Policies), that leverages human-driven priors, which are executed directly in the real world. In order to improve upon these priors, DEFT involves an efficient online optimization procedure. With the integration of human-based learning and online fine-tuning, coupled with a soft robotic hand, DEFT demonstrates success across various tasks, establishing a robust, data-efficient pathway toward general dexterous manipulation. |
|
|
Kenneth Shaw*, Shikhar Bahl*, Aravind Sivakumar, Aditya Kannan, Deepak Pathak IJRR 2023 Special Issue
abstract |
bibtex
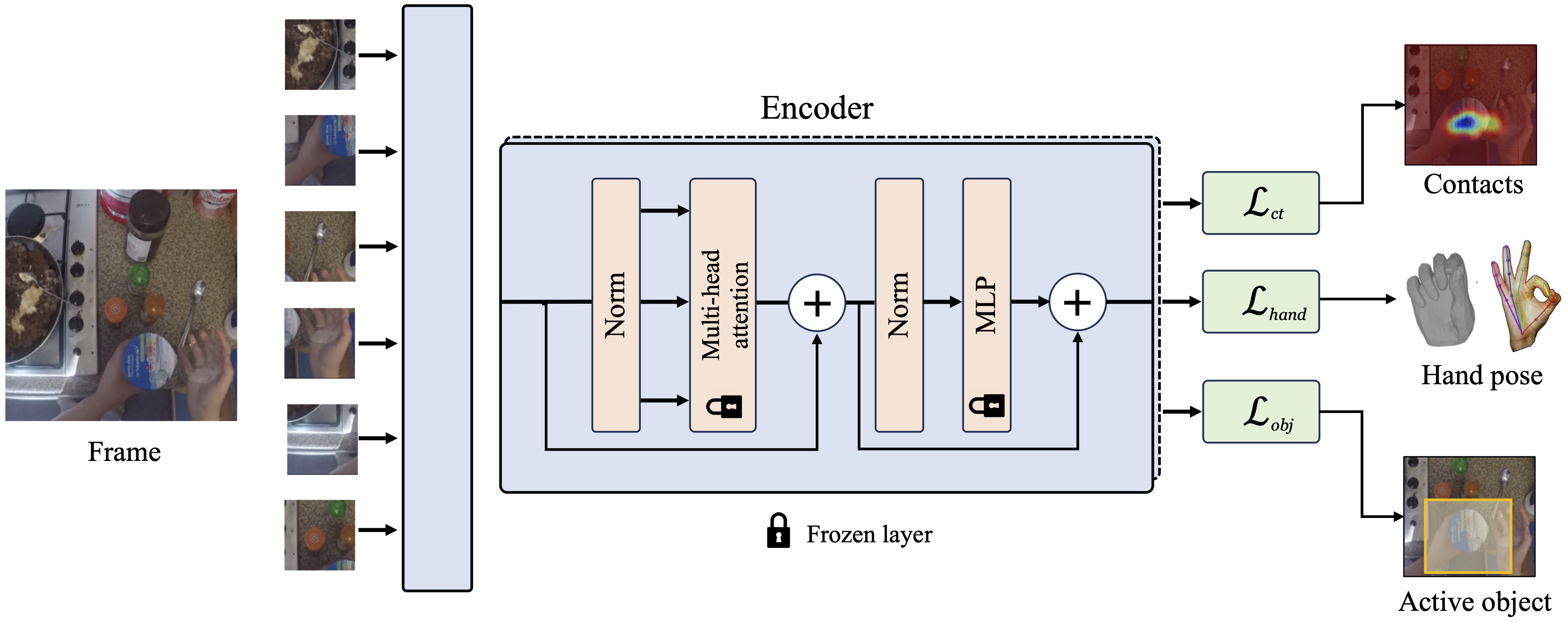
To build general robotic agents that can operate in many environments, it is often useful for robots to collect experience in the real world. However, unguided experience collection is often not feasible due to safety, time, and hardware restrictions. We thus propose leveraging the next best thing as real world experience: videos of humans using their hands. To utilize these videos, we develop a method that retargets any 1st person or 3rd person video of human hands and arms into the robot hand and arm trajectories. While retargeting is a difficult problem, our key insight is to rely on only internet human hand video to train it. We use this method to present results in two areas: First, we build a system that enables any human to control a robot hand and arm, simply by demonstrating motions with their own hand. The robot observes the human operator via a single RGB camera and imitates their actions in real-time. This enables the robot to collect real-world experience safely using supervision. Second, we retarget in-the-wild human internet video into task-conditioned pseudo-robot trajectories to use as artificial robot experience. This learning algorithm leverages action priors from human hand actions, visual features from the images, and physical priors from dynamical systems to pretrain typical human behavior for a particular robot task. We show that by leveraging internet human hand experience, we need fewer robot demonstrations compared to many other methods. |
|
|
webpage |
abstract |
bibtex |
arXiv
We tackle the problem of learning complex, general behaviors directly in the real world. We propose an approach for robots to efficiently learn manipulation skills using only a handful of real-world interaction trajectories from many different settings. Inspired by the success of learning from large-scale datasets in the fields of computer vision and natural language, our belief is that in order to efficiently learn, a robot must be able to leverage internet-scale, human video data. Humans interact with the world in many interesting ways, which can allow a robot to not only build an understanding of useful actions and affordances but also how these actions affect the world for manipulation. Our approach builds a structured, human-centric action space grounded in visual affordances learned from human videos. Further, we train a world model on human videos and fine-tune on a small amount of robot interaction data without any task supervision. We show that this approach of affordance-space world models enables different robots to learn various manipulation skills in complex settings, in under 30 minutes of interaction. |
|
|
webpage |
abstract |
bibtex |
pdf
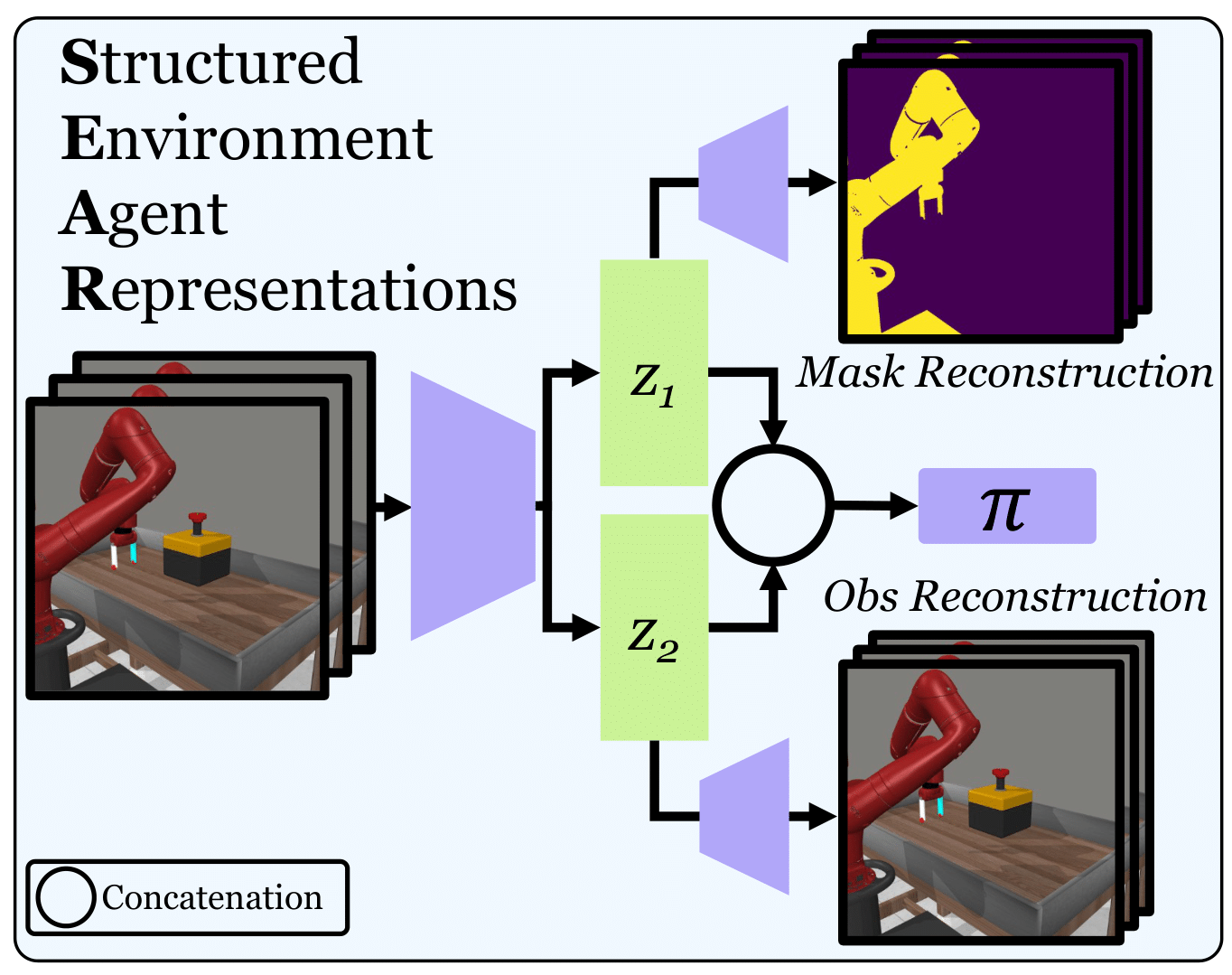
Agents that are aware of the separation between the environments and themselves can leverage this understanding to form effective representations of visual input. We propose an approach for learning such structured representations for RL algorithms, using visual knowledge of the agent, which is often inexpensive to obtain, such as its shape or mask. This is incorporated into the RL objective using a simple auxiliary loss. We show that our method, SEAR (Structured Environment-Agent Representations), outperforms state-of-the-art model-free approaches over 18 different challenging visual simulation environments spanning 5 different robots. |
|
webpage |
abstract |
bibtex |
arXiv |
code
Building a robot that can understand and learn to interact by watching humans has inspired several vision problems. However, despite some successful results on static datasets, it remains unclear how current models can be used on a robot directly. In this paper, we aim to bridge this gap by leveraging videos of human interactions in an environment centric manner. Utilizing internet videos of human behavior, we train a visual affordance model that estimates where and how in the scene a human is likely to interact. The structure of these behavioral affordances directly enables the robot to perform many complex tasks. We show how to seamlessly integrate our affordance model with four robot learning paradigms including offline imitation learning, exploration, goal-conditioned learning, and action parameterization for reinforcement learning. We show the efficacy of our approach, which we call Vision-Robotics Bridge (VRB) as we aim to seamlessly integrate computer vision techniques with robotic manipulation, across 4 real world environments, over 10 different tasks, and 2 robotic platforms operating in the wild. |
|
|
webpage |
abstract |
bibtex |
arXiv |
Robotic agents that operate autonomously in the real world need to continuously explore their environment and learn from the data collected, with minimal human supervision. While it is possible to build agents that can learn in such a manner without supervision, current methods struggle to scale to the real world. Thus, we propose ALAN, an autonomously exploring robotic agent, that can perform many tasks in the real world with little training and interaction time. This is enabled by measuring environment change, which reflects object movement and ignores changes in the robot position. We use this metric directly as an environment-centric signal, and also maximize the uncertainty of predicted environment change, which provides agent-centric exploration signal. We evaluate our approach on two different real-world play kitchen settings, enabling a robot to efficiently explore and discover manipulation skills, and perform tasks specified via goal images. |
|
|
webpage |
abstract |
bibtex |
arXiv |
demo
To build general robotic agents that can operate in many environments, it is often imperative for the robot to collect experience in the real world. However, this is often not feasible due to safety, time and hardware restrictions. We thus propose leveraging the next best thing as real world experience: internet videos of humans using their hands. Visual priors, such as visual features, are often learned from videos, but we believe that more information from videos can be utilized as a stronger prior. We build a learning algorithm, VideoDex, that leverages visual, action and physical priors from human video datasets to guide robot behavior. These action and physical priors in the neural network dictate the typical human behavior for a particular robot task. We test our approach on a robot arm and dexterous hand based system and show strong results on many different manipulation tasks, outperforming various state-of-the-art methods. |
|

|
webpage |
pdf |
abstract |
bibtex |
arXiv |
videos |
talk
We approach the problem of learning by watching humans in the wild. While traditional approaches in Imitation and Reinforcement Learning are promising for learning in the real world, they are either sample inefficient or are constrained to lab settings. Meanwhile, there has been a lot of success in processing passive, unstructured human data. We propose tackling this problem via an efficient one-shot robot learning algorithm, centered around learning from a third person perspective. We call our method WHIRL: In the Wild Human-Imitated Robot Learning. In WHIRL, we aim to use human videos to extract a prior over the intent of the demonstrator, and use this to initialize our agent's policy. We introduce an efficient real-world policy learning scheme, that improves over the human prior using interactions. Our key contributions are a simple sampling-based policy optimization approach, a novel objective function for aligning human and robot videos as well as an exploration method to boost sample efficiency. We show, one-shot, generalization and success in real world settings, including 20 different manipulation tasks in the wild.
@article{bahl2022human,
author = {Bahl, Shikhar and
Gupta, Abhinav and Pathak, Deepak},
title = {Human-to-Robot Imitation in the Wild},
journal= {RSS},
year = {2022}
}
|

|
webpage |
pdf |
abstract |
bibtex |
code
Benchmarks offer a scientific way to compare algorithms using objective performance metrics. Good benchmarks have two features: (a) they should be widely useful for many research groups; (b) and they should produce reproducible findings. In robotic manipulation research, there is a trade-off between reproducibility and broad accessibility. If the benchmark is kept restrictive (fixed hardware, objects), the numbers are reproducible but the setup becomes less general. On the other hand, a benchmark could be a loose set of protocols (e.g. YCB object set) but the underlying variation in setups make the results non-reproducible. In this paper, we re-imagine benchmarking for robotic manipulation as state-of-the-art algorithmic implementations, alongside the usual set of tasks and experimental protocols. The added baseline implementations will provide a way to easily recreate SOTA numbers in a new local robotic setup, thus providing credible relative rankings between existing approaches and new work. However, these 'local rankings' could vary between different setups. To resolve this issue, we build a mechanism for pooling experimental data between labs, and thus we establish a single global ranking for existing (and proposed) SOTA algorithms. Our benchmark, called Ranking-Based Robotics Benchmark (RB2), is evaluated on tasks that are inspired from clinically validated Southampton Hand Assessment Procedures. Our benchmark was run across two different labs and reveals several surprising findings. For example, extremely simple baselines like open-loop behavior cloning, outperform more complicated models (e.g. closed loop, RNN, Offline-RL, etc.) that are preferred by the field. We hope our fellow researchers will use RB2 to improve their research's quality and rigor.
@inproceedings{dasari2021rb2,
title={RB2: Robotic Manipulation
Benchmarking with a Twist},
author={Dasari, Sudeep and
Wang, Jianren and Hong, Joyce and
Bahl, Shikhar and Lin, Yixin and
Wang, Austin S and Thankaraj, Abitha
and Chahal, Karanbir Singh and
Calli, Berk and Gupta, Saurabh
and others},
booktitle={Thirty-fifth Conference
on Neural Information Processing
Systems Datasets and Benchmarks
Track (Round 2)},
year={2021}
}
|

|
webpage |
pdf |
abstract |
bibtex |
arXiv |
talk video
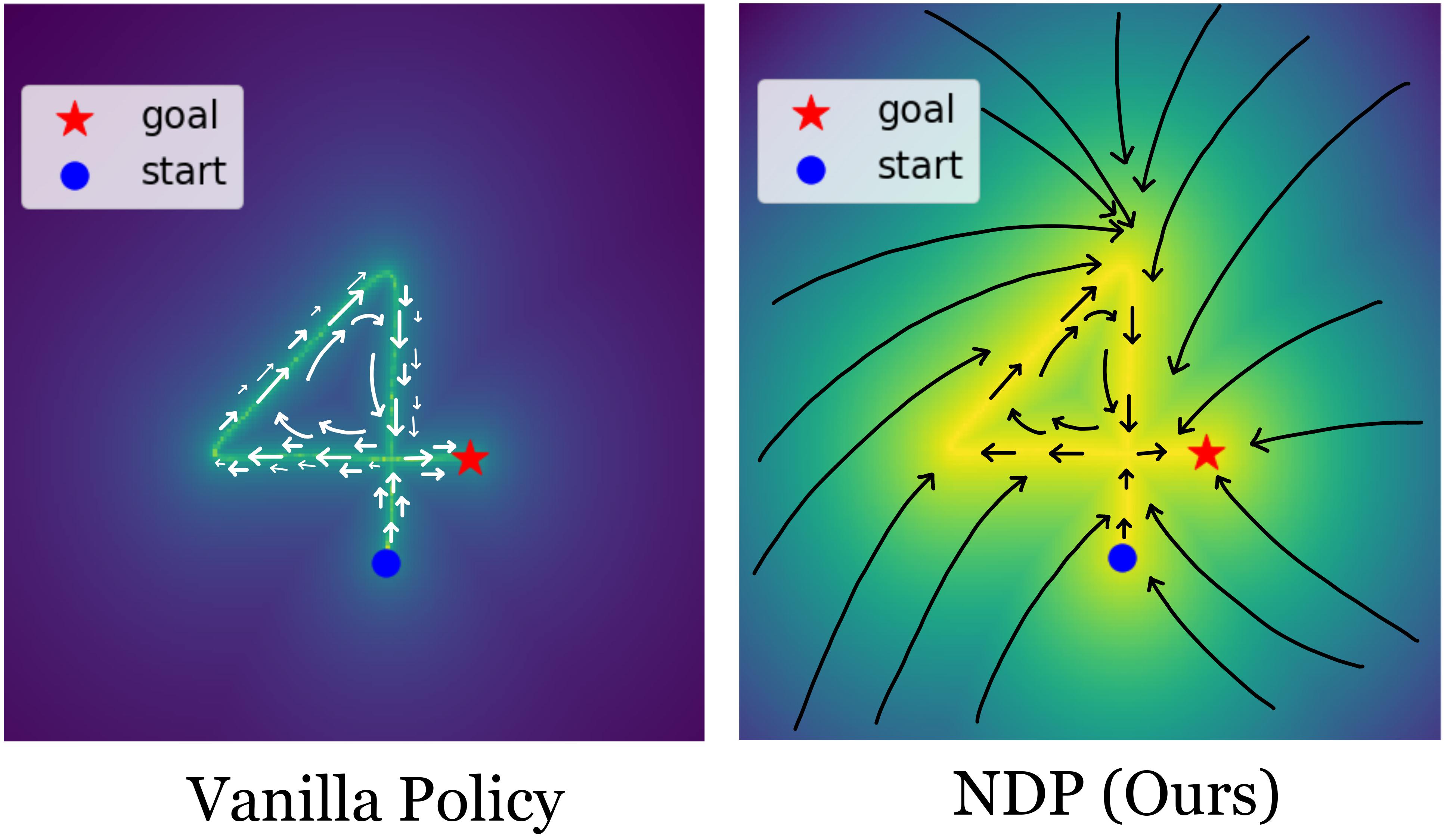
We tackle the problem of generalization to unseen configurations for dynamic tasks in the real world while learning from high-dimensional image input. The family of nonlinear dynamical system-based methods have successfully demonstrated dynamic robot behaviors but have difficulty in generalizing to unseen configurations as well as learning from image inputs. Recent works approach this issue by using deep network policies and reparameterize actions to embed the structure of dynamical systems but still struggle in domains with diverse configurations of image goals, and hence, find it difficult to generalize. In this paper, we address this dichotomy by leveraging embedding the structure of dynamical systems in a hierarchical deep policy learning framework, called Hierarchical Neural Dynamical Policies (H-NDPs). Instead of fitting deep dynamical systems to diverse data directly, H-NDPs form a curriculum by learning local dynamical system-based policies on small regions in state-space and then distill them into a global dynamical system-based policy that operates only from high-dimensional images. H-NDPs additionally provide smooth trajectories, a strong safety benefit in the real world. We perform extensive experiments on dynamic tasks both in the real world (digit writing, scooping, and pouring) and simulation (catching, throwing, picking). We show that H-NDPs are easily integrated with both imitation as well as reinforcement learning setups and achieve state-of-the-art results.
@article{bahl2021hndp,
author = {Bahl, Shikhar and
Gupta, Abhinav and Pathak, Deepak},
title = {Hierarchical Neural
Dynamic Policies},
journal= {RSS},
year = {2021}
}
|
 |
webpage |
pdf |
abstract |
bibtex |
arXiv |
code |
demo |
spotlight talk
The current dominant paradigm in sensorimotor control, whether imitation or reinforcement learning, is to train policies directly in raw action spaces such as torque, joint angle, or end-effector position. This forces the agent to make decision at each point in training, and hence, limit the scalability to continuous, high-dimensional, and long-horizon tasks. In contrast, research in classical robotics has, for a long time, exploited dynamical systems as a policy representation to learn robot behaviors via demonstrations. These techniques, however, lack the flexibility and generalizability provided by deep learning or deep reinforcement learning and have remained under-explored in such settings. In this work, we begin to close this gap and embed dynamics structure into deep neural network-based policies by reparameterizing action spaces with differential equations. We propose Neural Dynamic Policies (NDPs) that make predictions in trajectory distribution space as opposed to prior policy learning methods where action represents the raw control space. The embedded structure allow us to perform end-to-end policy learning under both reinforcement and imitation learning setups. We show that NDPs achieve better or comparable performance to state-of-the-art approaches on many robotic control tasks using both reward-based training and demonstrations.
@inproceedings{bahl2020ndp,
Author = {Bahl, Shikhar and
Mukadam, Mustafa and
Gupta, Abhinav and Pathak, Deepak},
Title = {Neural Dynamic Policies
for End-to-End Sensorimotor Learning},
Booktitle = {NeurIPS},
Year = {2020}
}
|
 |
webpage |
pdf |
abstract |
bibtex |
arXiv |
code |
video |
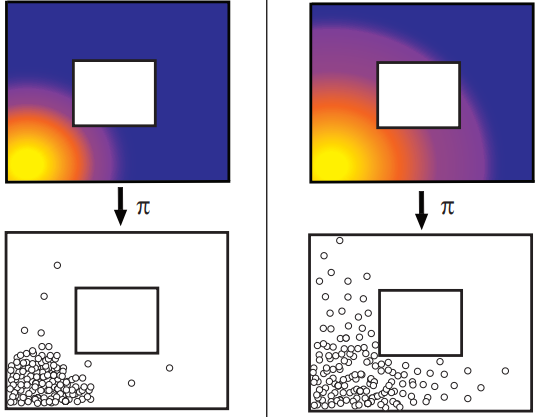
Reinforcement learning can enable an agent to acquire a large repertoire of skills. However, each new skill requires a manually-designed reward function, which typically requires considerable manual effort and engineering. Self-supervised goal setting has the potential to automate this process, enabling an agent to propose its own goals and acquire skills that achieve these goals. However, such methods typically rely on manually-designed goal distributions or heuristics to encourage the agent to explore a wide range of states. In this work, we propose a formal objective for exploration when training an autonomous goal-reaching policy that maximizes state coverage, and show that this objective is equivalent to maximizing the entropy of the goal distribution together with goal reaching performance. We present an algorithm called Skew-Fit for learning such a maximum-entropy goal distribution, and show that our method converges to a uniform distribution over the set of possible states, even when we do not know this set beforehand. When combined with existing goal-conditioned reinforcement learning algorithms, we show that Skew-Fit allows self-supervised agents to autonomously explore their entire state space faster than prior work, across a variety of simulated and real robotic tasks.
@inproceedings{bahl2020ndp,
title={Skew-fit: State-covering self-supervised reinforcement learning},
author={Pong, Vitchyr H and Dalal, Murtaza and Lin, Steven and Nair, Ashvin and Bahl, Shikhar and Levine, Sergey},
journal={ICML},
year={2020}
}
|

|
webpage |
pdf |
abstract |
bibtex |
arXiv |
video
We consider a variety of difficult industrial insertion tasks with visual inputs and different natural reward specifications, namely sparse rewards and goal images. We show that methods that combine RL with prior information, such as classical controllers or demonstrations, can solve these tasks from a reasonable amount of real-world interaction.
@article{nair2020contextual,
title={Deep reinforcement learning for industrial insertion tasks with visual inputs and natural rewards},
author={Schoettler, Gerrit and Nair, Ashvin and Luo, Jianlan and Bahl, Shikhar and Ojea, Juan Aparicio and Solowjow, Eugen and Levine, Sergey},
booktitle={IROS},
year={2020},
}
|

|
webpage |
pdf |
abstract |
bibtex |
arXiv |
code |
data |
video
We propose a conditional goal-setting model that aims to only propose goals that are feasible reachable from the robot's current state, and demonstrate that this enables self-supervised goal-conditioned learning with raw image observations both in varied simulated environments and a real-world pushing task..
@article{nair2020contextual,
title={Contextual imagined goals for self-supervised robotic learning},
author={Nair, Ashvin and Bahl, Shikhar and Khazatsky, Alexander and Pong, Vitchyr and Berseth, Glen and Levine, Sergey},
booktitle={CoRL},
year={2020},
}
|
 |
webpage |
pdf |
abstract |
bibtex |
arXiv |
video
Conventional feedback control methods can solve various types of robot control problems very efficiently by capturing the structure with explicit models, such as rigid body equations of motion. However, many control problems in modern manufacturing deal with contacts and friction, which are difficult to capture with first-order physical modeling. Hence, applying control design methodologies to these kinds of problems often results in brittle and inaccurate controllers, which have to be manually tuned for deployment. Reinforcement learning (RL) methods have been demonstrated to be capable of learning continuous robot controllers from interactions with the environment, even for problems that include friction and contacts. In this paper, we study how we can solve difficult control problems in the real world by decomposing them into a part that is solved efficiently by conventional feedback control methods, and the residual which is solved with RL. The final control policy is a superposition of both control signals. We demonstrate our approach by training an agent to successfully perform a real-world block assembly task involving contacts and unstable objects
@inproceedings{johannink2019residual,
title={Residual reinforcement learning for robot control},
author={Johannink, Tobias and Bahl, Shikhar and Nair, Ashvin and Luo, Jianlan and Kumar, Avinash and Loskyll, Matthias and Ojea, Juan Aparicio and Solowjow, Eugen and Levine, Sergey},
booktitle={ICRA},
year={2019},
}
}
|
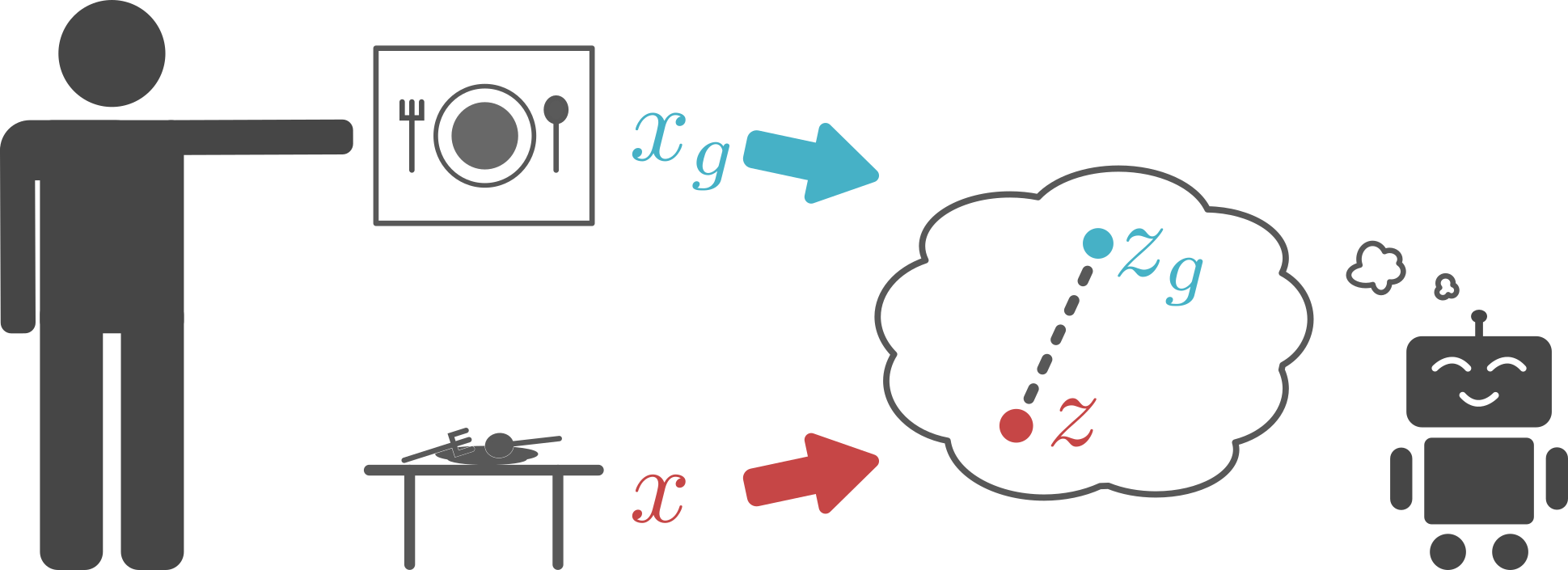 |
webpage |
pdf |
abstract |
bibtex |
arXiv |
code |
blog |
videos
For an autonomous agent to fulfill a wide range of user-specified goals at test time, it must be able to learn broadly applicable and general-purpose skill repertoires. Furthermore, to provide the requisite level of generality, these skills must handle raw sensory input such as images. In this paper, we propose an algorithm that acquires such general-purpose skills by combining unsupervised representation learning and reinforcement learning of goal-conditioned policies. Since the particular goals that might be required at test-time are not known in advance, the agent performs a self-supervised "practice" phase where it imagines goals and attempts to achieve them. We learn a visual representation with three distinct purposes: sampling goals for self-supervised practice, providing a structured transformation of raw sensory inputs, and computing a reward signal for goal reaching. We also propose a retroactive goal relabeling scheme to further improve the sample-efficiency of our method. Our off-policy algorithm is efficient enough to learn policies that operate on raw image observations and goals for a real-world robotic system, and substantially outperforms prior techniques.
@article{nair2018visual,
title={Visual reinforcement learning with imagined goals},
author={Nair, Ashvin V and Pong, Vitchyr and Dalal, Murtaza and Bahl, Shikhar and Lin, Steven and Levine, Sergey},
journal={NeurIPS},
year={2018}
}
|
|
|
 |
|
|