The current dominant paradigm in sensorimotor control, whether imitation or reinforcement learning, is to train policies directly in raw action spaces such as torque, joint angle, or end-effector position. This forces the agent to make decision at each point in training, and hence, limit the scalability to continuous, high-dimensional, and long-horizon tasks. In contrast, research in classical robotics has, for a long time, exploited dynamical systems as a policy representation to learn robot behaviors via demonstrations. These techniques, however, lack the flexibility and generalizability provided by deep learning or deep reinforcement learning and have remained under-explored in such settings. In this work, we begin to close this gap and embed dynamics structure into deep neural network-based policies by reparameterizing action spaces with differential equations. We propose Neural Dynamic Policies (NDPs) that make predictions in trajectory distribution space as opposed to prior policy learning methods where action represents the raw control space. The embedded structure allow us to perform end-to-end policy learning under both reinforcement and imitation learning setups. We show that NDPs achieve better or comparable performance to state-of-the-art approaches on many robotic control tasks using reward-based training, as well as on digit writing using demonstrations.
Neural Dynamic Policies
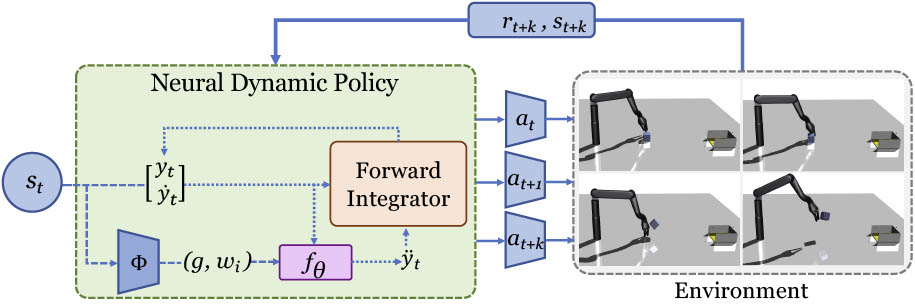
Given an observation from the environment, a Neural Dynamic Policy generates parameters (weights of basis functions and goal for the robot) for a forcing function. An open loop controller then uses this function to output a set of actions for the robot to execute in the environment, collecting future states and rewards to train the policy.
Source Code
We have released the PyTorch based implementation and our environments on github. Try our code!
|
|
Paper and Bibtex

|
Citation |
|
@inproceedings{bahl2020neural,
title={Neural Dynamic Policies
for End-to-End Sensorimotor Learning},
author={Bahl, Shikhar and Mukadam, Mustafa
and Gupta, Abhinav and Pathak, Deepak},
year={2020},
booktitle={NeurIPS}
}
|